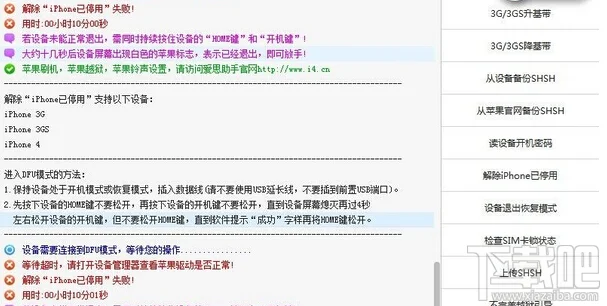
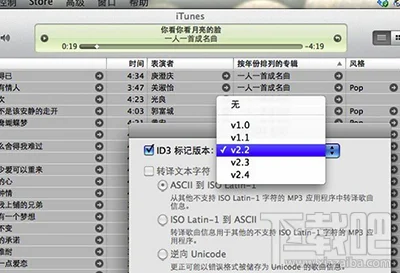
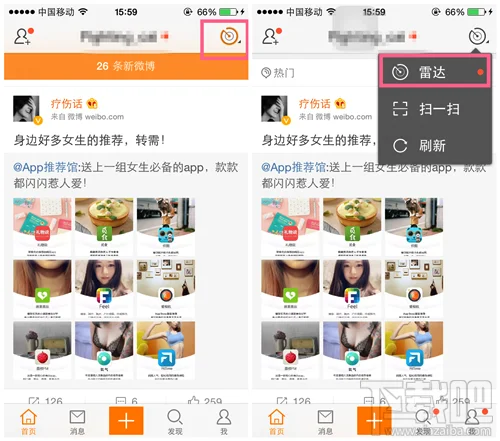
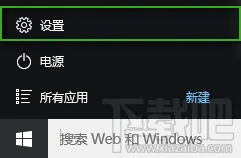
Microsoft Excel 教程,如何在 Excel
756 2023-04-03 05:09:57

link:https://arxiv.org/abs/1812.09430
提出了在动态图上使用自注意力
本文提出了使用自注意力的网络结构用于在动态图学习节点表示。具体地说,DySAT使用(1)结构邻居和(2)历史节点表示上的自我注意来计算动态节点表示,虽然实验是在没有节点特征的图上进行的,但DySAT可以很容易地推广到特征丰富的图上。另一个有趣的方向是探索框架的连续时间泛化,以包含更细粒度的时间变化。
图1:DySAT的结构,采用了两个自注意力的结构,结构自注意力后接时序自注意力。黑色虚线表示新连接,蓝色虚线表示基于邻居的结构注意力
表1:数据集参数
表2:链接预测的sota(DynGEM在这确实不好 不过毕竟别人的卖点是稳定性)
图2:在不同时间步的表现对照
照例提了一下将节点嵌入的方法效果不错,但是动态图有时间信息,前人的工作没有考虑时间信息或者只是用快照+时间正则化的的方法。
注意力机制在序列任务中获得了巨大成功。关键是学习一个函数,该函数可以进行加权求和权重即为注意力,同时关注与特定上下文最相关的部分。当注意机制使用单一序列作为输入和上下文时,通常称为自我注意
DySAT通过在邻居和时间序列上做注意力机制以反映图结构在不同数量的历史快照上的时间演化。与基于时间平滑度的方法相比,DySAT学习的注意力权重能够在细粒度节点级粒度上捕获时间依赖性。
定义了一些参数
动态图定义为一组时间步
其中每个快照表示为
节点
DySAT由两个组件构成:结构注意力块、时间注意力块。与已有的注意机制研究类似,采用多头注意来提高模型容量和稳定性。
DySAT的组成是结构自注意力块后接着时间注意力块,如图1。其中每个组件可能包含对应层类型的多个堆叠层。结构块(结构自注意力块,下同)通过自注意力聚合提取邻居特征,为快照计算该节点嵌入。这些嵌入作为时间快的输入提供,时间块在多个时间步上出现,捕捉图形中的时间变化。
基于GAT的思路,结构块的注意力公式如下
参数解释:
||:拼接操作
在上式中先使用LeakyRELU计算注意力权重,接着使用ELU计算输出表示
上面两种激活函数都是RELU的改版,RELU在值小于0时容易造成梯度消失,所以有一些变种RELU,主要还是改动负半轴的的函数
LeakyRELU将负半轴改为
ELU将负半轴改为
在我们的实验中,我们使用稀疏矩阵来实现对邻居的mask自注意力。
该层的输入是特定节点v在不同时间步的一系列表示。
该层的输入是
该层的输出是
将以上的向量表示改变为矩阵:
时间自注意力机制的目标是捕获在图结构上的多个时间步下的时序信息变化,在时间
为了计算
说一下为什么要使用缩放的点积注意力(为什么要除
其中其中查询、键和值被设置为输入节点表示(qkv矩阵)。首先使用线性投影矩阵
参数解释:
所以将
本文还采取了多头注意力的机制(类似cnn中的改变通道数,对节点的每个表示使用多通道叠加的概念)
我们在结构和时间自我注意层中使用多个注意头,然后连接:
结构多头自注意力:
时间多头自注意力:
其中
这节介绍模型结构,整个模型由三个模块构成:
结构块,时序块,图上下文预测
该模型以一组T图快照作为输入,并在每个时间步生成节点嵌入
结构注意力块:该模块由多个堆叠的结构自我注意层组成,用于从不同距离的节点中提取特征。如图1所示,在具有共享参数的不同快照上独立应用每一层,以在每个时间步捕获节点周围的局部邻域结构。该层的输出为
时间注意力块:通过位置嵌入(position embedding)为时间注意力模块提供顺序信息。将位置嵌入表示为为
然后将位置嵌入与结构注意块的输出相结合
图上下文预测:为了确保学习到的表示同时捕获结构和时间信息,我们定义了一个目标函数,该函数跨多个时间步保留节点周围的局部结构。使用节点
参数解释:
σ:sigmoid
< . >:向量点乘
选取链接预测作为模型性能表示
数据集是4个,两个通信网络,两个二部图评分网络
具体见表1
在快照
在
除非有明文规定,对于所有的方法,节点对的特征表示都是使用Hadamard积
优化器:Adam。对于 Enron,在结构块和时间块中使用一个单层,每层由16个注意力头组成,每个注意力头计算8个特征(总共128个维度)。在其他数据集中,使用了两个自注意力层,分别有16个和8个头部,每个头部计算16个特征(层大小为256,128)。该模型最多可训练200个轮次,批量大小为256个节点,并选择验证集中性能最好的模型进行评估。
除了和动态图算法比较,还比较了几种静态图嵌入方法,以分析使用时间信息进行动态链路预测的收益。为了与静态方法进行公平比较,我们通过构建一个到时间t的聚合图来合并快照的整个历史,其中每个链接的权重被定义为到时间t为止的累积权重,与它的发生时间无关。我们为所有基线使用作者提供的实现,并设置最终嵌入维度d=128。
对比了静态方法的node2vec,graphSage,graph autoencoders。在GraphPage中使用不同的聚合器进行实验,即GCN、平均池、最大池和LSTM,以报告每个数据集中性能最好的聚合器的性能。为了与GAT进行公平比较,GAT最初只对节点分类进行实验,论文在GraphSAGE中实现了一个图形注意层作为额外的聚合器,用GraphSAGE+GAT表示。本文还将GCN和GAT训练为自动编码器,用于沿着(Modeling polypharmacy side effects with graph convolutional networks)的建议线路进行链路预测,分别用GCN-AE和GAT-AE表示。
在动态环境中,根据最新的动态图嵌入研究,包括Know Evolve、DynamicRiad和DynGEM,对DySAT进行评估。所有方法的超参数调整详情见附录F。
在每个时间步t对模型进行评估,方法是将单独的模型训练到快照t,并在t+1对每个t进行评估,总结了表2中所有模型的微观和宏观平均AUC分数(跨越所有时间步)。从结果中,我们观察到,与所有数据集的最佳基线相比,DySAT实现了3–4%宏观AUC的一致增益。此外,还比较了每个时间步的模型性能(图2),以深入了解它们的时间行为。论文对DySAT的性能进行了优化,使其比其他方法更稳定。这种对比在通信网络(安然和UCI)中表现得尤为明显,观察到静态嵌入方法在特定时间步的性能急剧下降。
在ML-10M上,使用一台配备Nvidia Tesla V100 GPU和28个CPU内核的机器,每小批DySAT的运行时间为0.72秒。相比之下,没有时间注意的模型变量(附录a)需要0.51秒,这说明时间注意的成本相对较低。
原文提出了一些观察,这里直接翻译了:
实验结果为不同图形嵌入技术的性能提供了一些有趣的观察和见解。
首先,观察到GraphSAGE在不同的数据集上实现了与DynamicRiad相当的性能,尽管它只接受静态图的训练。一种可能的解释是,GraphSAGE使用可训练的邻居聚合函数,而DynamicRiad使用基于Skipgram的方法,并增加了时间平滑度。 所以结构和时间建模与表达聚合功能(如多头注意)的结合,是DySAT在动态链接预测方面始终表现优异的原因。还观察到node2vec实现了与时间信息无关的一致性能,这证明了二阶随机游走采样的有效性。这一观察结果为应用抽样技术进一步改善DySAT指明了方向。
还观察到node2vec实现了与时间信息无关的性能,这证明了二阶随机游走采样的有效性
在DySAT中,我们采用结构注意层,然后是时间注意层。我们之所以选择这种设计,是因为图形结构随着时间的推移并不稳定,这使得在时间注意层之后直接使用结构注意层是不可行的。论文还考虑了另一种替代设计选择,即按照类似于(Shen等人,2018年)的策略,在邻居和时间这两个维度上一起使用自我关注。实际上,由于多个快照中每个节点的邻居数量可变,这在计算上会非常昂贵。
在当前设置中,使用稀疏矩阵将每个快照的邻接矩阵存储在内存中,这在缩放到大型图时可能会带来内存挑战。在未来,作者计划沿着GraphSAGE的路线,探索具有记忆效率的小批量训练策略的DySAT。此外,我们开发了一个增量自我注意网络(IncSAT),作为DySAT的直接扩展,它在计算和记忆成本方面都是有效的。正如附录E所报告的,我们的初步结果是有希望的,这为将来探索增量(或流式)图形表征学习的自我注意架构打开了大门。我们还评估了DySAT在多步链路预测或预测方面的能力,并观察到与现有方法相比平均6%AUC的显著相对改善,如附录C所述。
这篇论文的embedding是使用独热码作为输入,引入了自注意力机制并尝试在动态图上使用,并且还引入的pos嵌入的思路(Convolutional sequence to sequence learning)以保证顺序,读了四篇论文,慢慢开始有感觉了,现在读一篇论文加上理解内容已经比原来快很多了,很多参数和公式看一眼就知道咋回事了,基本上都是翻来覆去的各种搭积木