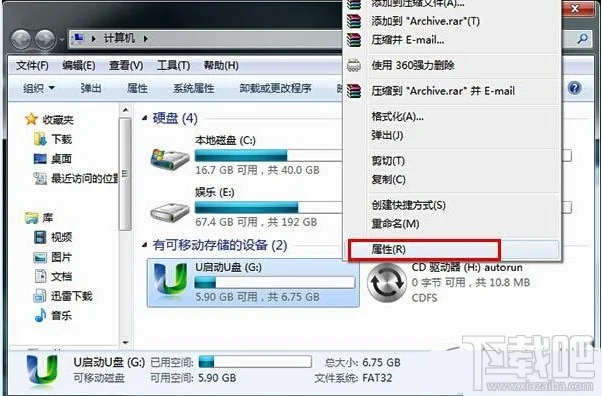
1分钟了解MyISAM与InnoDB的索引差
462 2023-04-03 03:03:08
现在深度学习框架越来越多。如果有机会我想造个新轮子:深度学习专用语言。预计未来会是像 TVM 这种 IR 路线:前端按个人爱好,后端编译到各种硬件和芯片。
言归正传。总结整理了1张图,基于各自的 autograd 系统。所有框架在运行后可以得到一致的结果。让大家一目了然,省下重复学习的时间。
从图中可以看到,各个动态图框架在一些琐碎问题上的不同取舍,例如:
个人较为偏向 PyTorch 的大部分抉择。下一张图再总结加入网络层后的各个框架的比较。
深度学习框架的难点还是大规模并行化,这方面不同框架还是有区别的。
附 MXNet 版本的代码方便大家复制黏贴:
import numpy as npN, D_in, H, D_out = 3, 2, 2, 1 # N = 批大小, D_in = 输入维数, H = 中间维数, D_out = 输出维数x0 = np.array([[-0.5, 1], [0.2, -0.6], [0., 0.5]]) # 输入数据y0 = np.array([[1], [0.2], [0.5]]) # 输出数据w1_0 = np.array([[0.5, 0], [-0.5, 1]]) # 第 1 层初始权重w2_0 = np.array([[-0.5], [0.5]]) # 第 2 层初始权重learning_rate = 0.1 # 学习速率n_epoch = 2 # 训练 epoch 数import mxnet as mxfrom mxnet import nd, autogradx = nd.array(x0) # 注意 MXNet 默认即为 float32y = nd.array(y0)w1 = nd.array(w1_0)w2 = nd.array(w2_0)w1.attach_grad() # 需要梯度w2.attach_grad() # 需要梯度for t in range(n_epoch): with autograd.record(): # 注意 MXNet 默认关闭梯度,在此打开 y_pred = nd.dot(nd.dot(x, w1).relu(), w2) loss = ((y_pred - y) ** 2.0).sum() / N loss.backward() w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad print('=== EPOCH', t, 'loss', loss, '===') print('out', y_pred) print('w1_new', w1) print('w2_new', w2, '\n')还没有安装 PyTorch+TensorFlow+MXNet 的同学可以看我在专栏的另一个文章:
PENG Bo:Windows装TensorFlow+MXNet+PyTorchzhuanlan.zhihu.com